5.2b Agent 设计模式
来源:Anthropic《Building Effective Agents》、Lilian Weng《LLM Powered Autonomous Agents》
📝 课程笔记
本课核心知识点整理:
学完你能做什么
- 选择合适的 Agent 架构
- 实现五种 Workflow 模式
- 设计复杂的多 Agent 协作系统
- 避免常见的设计陷阱
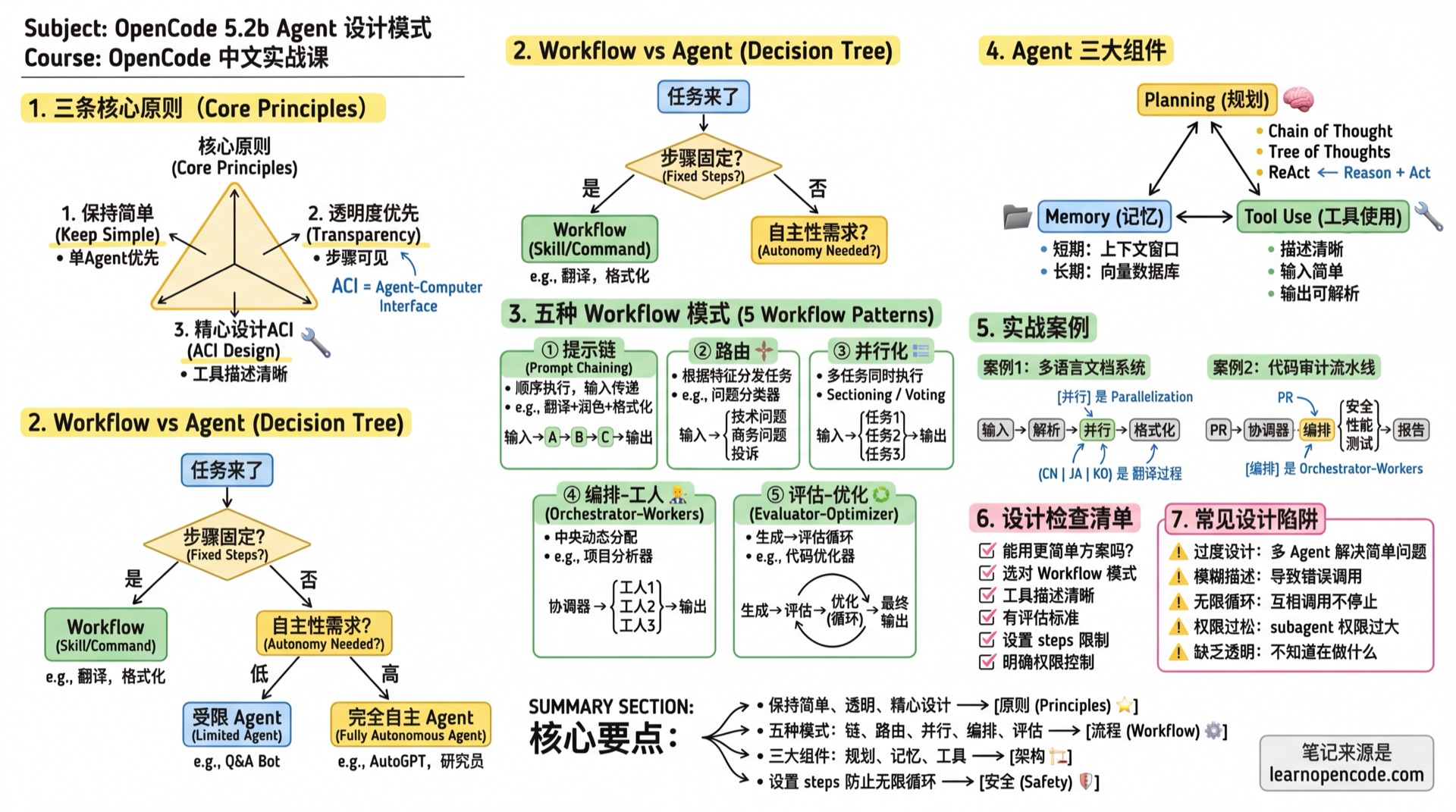
核心原则
Anthropic 在与数十个团队合作构建 Agent 后总结出三条核心原则:
1. 保持简单
"最成功的实现使用简单、可组合的模式,而非复杂框架。"
实践:
- 能用单个 Agent 解决的,不要用多个
- 能用固定流程的,不要用动态决策
- 能用 prompt 解决的,不要加工具
2. 透明度优先
"显式展示 Agent 的规划步骤。"
实践:
- Agent 的思考过程应该可见
- 每个步骤都有明确的输入输出
- 用户能理解 Agent 在做什么
3. 精心设计工具接口(ACI)
"像设计人机界面(HCI)一样投入精力设计 Agent-计算机界面(ACI)。"
实践:
- 工具描述要像给初级开发者写的优秀 docstring
- 包含使用示例和边界情况
- 避免需要精确计数或复杂转义的格式
Workflow vs Agent:如何选择
| 类型 | 特点 | 适用场景 | OpenCode 实现 |
|---|---|---|---|
| Workflow | 预定义代码路径,步骤固定 | 任务可预测、结构清晰 | Skill、Command |
| Agent | LLM 动态决策,自主探索 | 开放性问题、无法预测步骤 | Agent + Task tool |
选择流程图
任务来了
↓
步骤是否固定?
├─ 是 → 用 Workflow(Skill/Command)
└─ 否 → 需要多少自主性?
├─ 低 → 受限 Agent(steps + 权限控制)
└─ 高 → 完全自主 Agent五种 Workflow 模式
模式 1:Prompt Chaining(提示链)
原理:将任务分解为顺序执行的步骤,每一步的输出是下一步的输入。
适用场景:
- 任务可以清晰分解为固定子任务
- 需要用延迟换取准确性
示例:翻译 + 润色 + 格式化
---
description: 多步骤翻译处理
mode: subagent
steps: 10
---
# 任务流程
按以下步骤执行,每步完成后再进行下一步:
## 步骤 1:直译
将原文逐句翻译成中文,保持原意。
## 步骤 2:意译润色
在直译基础上,调整为通顺的中文表达。
## 步骤 3:专业术语检查
检查专业术语是否准确,必要时保留英文。
## 步骤 4:格式化
按照目标格式(Markdown)整理输出。
# 输出要求
每个步骤都输出中间结果,最后给出最终版本。模式 2:Routing(路由)
原理:根据输入特征,将任务导向不同的专门处理流程。
适用场景:
- 不同类别需要不同处理方式
- 分类可以准确完成
示例:代码问题分类器
---
description: 代码问题分类路由器
mode: subagent
---
# 角色
你是代码问题分类专家,负责将问题路由到正确的处理流程。
# 分类规则
分析用户的代码问题,判断属于以下哪一类:
1. **Bug 修复** → 调用 @bug-fixer
- 特征:代码报错、行为不符合预期
2. **性能优化** → 调用 @performance-optimizer
- 特征:运行慢、内存占用高
3. **安全审计** → 调用 @security-auditor
- 特征:涉及认证、数据处理、外部输入
4. **代码重构** → 调用 @refactor-expert
- 特征:代码可以工作但需要改进结构
5. **新功能开发** → 不路由,直接处理
- 特征:实现新需求
# 输出格式
先说明分类理由,然后调用相应的 subagent。配合 Task 权限控制:
{
"agent": {
"router": {
"description": "代码问题分类路由器",
"mode": "primary",
"permission": {
"task": {
"*": "deny",
"bug-fixer": "allow",
"performance-optimizer": "allow",
"security-auditor": "allow",
"refactor-expert": "allow"
}
}
}
}
}模式 3:Parallelization(并行化)
原理:多个任务同时执行,最后汇总结果。
两种变体:
- Sectioning(分片):独立子任务并行
- Voting(投票):同一任务多视角验证
适用场景:
- 子任务相互独立
- 需要多视角提高准确性
- 时间敏感,需要加速
示例:代码质量并行检查
---
description: 代码质量并行检查器
mode: subagent
---
# 任务
对给定代码同时进行多维度检查。
# 并行任务
**同时**调用以下 subagent(使用多个 Task tool 调用):
1. @security-auditor - 安全漏洞检查
2. @performance-reviewer - 性能分析
3. @style-checker - 代码风格检查
4. @test-coverage-analyzer - 测试覆盖分析
# 汇总规则
收集所有结果后,生成综合报告:
## 综合评分
- 安全性:X/10
- 性能:X/10
- 代码风格:X/10
- 测试覆盖:X/10
- **总分**:X/40
## 问题汇总
按严重程度排序所有发现的问题。
## 优先修复建议
给出最应该优先处理的 3 个问题。模式 4:Orchestrator-Workers(编排-工人)
原理:中央 LLM(编排器)动态分析任务,将其分解并分配给专门的 Worker Agent。
适用场景:
- 无法预测需要哪些子任务
- 任务复杂度不确定
- 需要灵活应对
示例:项目分析编排器
---
description: 项目分析编排器,动态分配分析任务
mode: primary
---
# 角色
你是项目分析编排器,负责理解用户需求并协调专家团队。
# 可用专家
你可以调用以下专家(根据需要选择):
- @architecture-analyst - 架构分析,适合"这个项目结构怎么样"
- @dependency-auditor - 依赖审计,适合"有没有过时/危险的依赖"
- @security-auditor - 安全审计,适合"有没有安全隐患"
- @performance-profiler - 性能分析,适合"哪里可能是瓶颈"
- @docs-reviewer - 文档评审,适合"文档是否完整"
- @test-analyzer - 测试分析,适合"测试覆盖是否足够"
# 工作流程
1. **理解需求**:分析用户想知道什么
2. **制定计划**:决定需要调用哪些专家,以什么顺序
3. **执行分析**:调用选定的专家
4. **整合结果**:汇总所有专家的发现
5. **给出建议**:基于整体分析给出行动建议
# 原则
- 不要过度分析,根据用户需求选择必要的专家
- 如果用户问题简单,可能不需要任何专家
- 专家的分析结果可能会触发更多分析需求模式 5:Evaluator-Optimizer(评估-优化)
原理:一个 Agent 生成内容,另一个 Agent 评估,循环直到满足标准。
适用场景:
- 有明确的评估标准
- 迭代改进有价值
- 类似人类的"写作-修改"过程
示例:代码优化循环
---
description: 迭代代码优化器
mode: subagent
steps: 15
---
# 角色
你是代码优化专家,通过迭代改进代码质量。
# 优化循环
执行以下循环,直到满足目标或达到步数限制:
## 1. 分析阶段
- 阅读当前代码
- 识别可优化点
- 评估当前质量分数(见评分标准)
## 2. 优化阶段
- 选择影响最大的优化点
- 实施优化
- 确保不破坏功能
## 3. 验证阶段
- 运行测试确保功能正常
- 重新评估质量分数
## 4. 决策阶段
- 如果质量分数 >= 8,停止优化
- 如果质量分数提升 < 0.5,停止(边际效益不足)
- 否则,继续下一轮
# 质量评分标准
| 分数 | 可读性 | 性能 | 安全性 | 测试覆盖 |
|------|--------|------|--------|---------|
| 9-10 | 命名清晰、注释完整 | O(n)或更优 | 无漏洞 | >90% |
| 7-8 | 命名合理、关键注释 | O(n log n) | 低风险 | 70-90% |
| 5-6 | 基本可读 | O(n²) | 中风险 | 50-70% |
| <5 | 难以理解 | O(n³)+ | 高风险 | <50% |
综合得分 = 可读性×0.3 + 性能×0.3 + 安全性×0.25 + 测试覆盖×0.15
# 输出
每轮输出:
- 本轮优化内容
- 各维度得分明细
- 质量分数变化
- 是否继续的决策理由
最终输出:
- 优化总结
- 前后对比
- 进一步优化建议(如有)
# 失败处理
- 测试失败:立即回滚本轮修改,记录失败原因,尝试其他优化方向
- 步数耗尽:输出当前最佳版本和剩余优化建议
- 无法继续优化:说明原因,给出已达到的质量水平Agent 三大组件设计
根据 Lilian Weng 的研究,一个完整的 Agent 系统包含三大组件:
1. Planning(规划)
任务分解技术:
| 技术 | 说明 | 适用场景 |
|---|---|---|
| Chain of Thought | "一步步思考" | 通用推理 |
| Tree of Thoughts | 探索多个推理路径 | 复杂决策 |
| ReAct | 思考-行动-观察循环 | 需要与环境交互 |
在 Agent prompt 中应用:
# 工作方式
采用 ReAct 模式:
1. **思考**:分析当前状态,决定下一步
2. **行动**:执行具体操作(调用工具)
3. **观察**:分析操作结果
4. **重复**:直到任务完成2. Memory(记忆)
| 类型 | 对应 | 特点 |
|---|---|---|
| 短期记忆 | 上下文窗口 | 有限,约几万 token |
| 长期记忆 | 外部向量库 | 无限,需要检索 |
OpenCode 中的实现:
- 短期:会话上下文
- 长期:MCP 集成向量数据库
3. Tool Use(工具使用)
工具设计原则:
- 描述清晰:像给初级开发者的 docstring
- 输入简单:避免复杂的格式要求
- 输出可解析:结构化,便于后续处理
- 错误友好:清晰的错误信息
实战案例 1:多语言文档生成系统
动手提醒
本案例中的 @doc-parser、@translator-zh 等都是示例名称,OpenCode 没有内置这些 Agent。你需要按照 5.2a Agent 快速入门 学到的方法自己创建它们。
好消息是:案例 1 中的 Agent 比较简单,description 字段本身就是一个够用的 prompt,配合低 temperature 就能工作。不需要额外写 .md 文件。
需求:自动将 API 文档翻译成多语言版本。
系统设计
用户输入 API 文档
↓
@doc-parser(解析文档结构)
↓
@translator-zh(翻译成中文)
@translator-ja(翻译成日文) ← 并行
@translator-ko(翻译成韩文)
↓
@doc-formatter(格式化输出)
↓
多语言文档配置文件
// opencode.json
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"doc-generator": {
"description": "多语言文档生成编排器",
"mode": "primary",
"prompt": "{file:./prompts/doc-generator.md}",
"permission": {
"task": {
"*": "deny",
"doc-parser": "allow",
"translator-*": "allow",
"doc-formatter": "allow"
}
}
},
"doc-parser": {
"description": "解析 API 文档结构,提取可翻译内容",
"mode": "subagent",
"temperature": 0.1
},
"translator-zh": {
"description": "英译中专家,保持技术术语准确",
"mode": "subagent",
"temperature": 0.3
},
"translator-ja": {
"description": "英译日专家",
"mode": "subagent",
"temperature": 0.3
},
"translator-ko": {
"description": "英译韩专家",
"mode": "subagent",
"temperature": 0.3
},
"doc-formatter": {
"description": "文档格式化,确保多语言版本格式一致",
"mode": "subagent",
"temperature": 0.1
}
}
}编排器 Prompt
<!-- prompts/doc-generator.md -->
---
description: 多语言文档生成编排器
mode: primary
---
# 角色
你是多语言文档生成系统的编排器。
# 工作流程
## 1. 解析阶段
调用 @doc-parser 分析输入文档:
- 提取标题、描述、参数、返回值等结构
- 标记哪些内容需要翻译
- 哪些内容保持原样(如代码示例)
## 2. 翻译阶段
**并行**调用翻译专家:
- @translator-zh:翻译成中文
- @translator-ja:翻译成日文
- @translator-ko:翻译成韩文
告诉每个翻译专家:
- 文档结构
- 需要翻译的内容
- 术语表(如有)
## 3. 格式化阶段
调用 @doc-formatter:
- 将各语言版本整合
- 确保格式一致
- 生成最终输出
# 输出格式
生成包含所有语言版本的目录结构建议。实战案例 2:代码审计流水线
动手提醒
本案例中的 @security-auditor、@test-auditor 等都是示例名称,OpenCode 没有内置这些 Agent。你需要按照 5.2a Agent 快速入门 学到的方法自己创建它们。
和案例 1 不同,审计类的 Agent 需要专业的 prompt 才能给出有价值的分析结果。下面会给出完整的创建示例。
需求:对 PR 进行全方位代码审计。
系统设计
采用 Parallelization + Orchestrator-Workers 混合模式。
PR 代码变更
↓
@audit-coordinator(协调器)
↓
┌──────────────────────────────────┐
│ 并行执行(Sectioning) │
│ @security-auditor │
│ @performance-auditor │
│ @quality-auditor │
│ @test-auditor │
└──────────────────────────────────┘
↓
汇总所有发现
↓
@report-generator(生成报告)
↓
审计报告配置文件
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"audit-coordinator": {
"description": "代码审计协调器,编排多维度审计",
"mode": "subagent",
"model": "anthropic/claude-opus-4-5-thinking",
"prompt": "{file:./prompts/audit-coordinator.md}",
"steps": 50
},
"security-auditor": {
"description": "安全漏洞审计:注入、认证、数据泄露",
"mode": "subagent",
"temperature": 0.1,
"prompt": "{file:./prompts/security-auditor.md}",
"permission": {
"edit": "deny"
}
},
"performance-auditor": {
"description": "性能审计:复杂度、内存、并发",
"mode": "subagent",
"temperature": 0.1,
"permission": {
"edit": "deny"
}
},
"quality-auditor": {
"description": "代码质量审计:可读性、SOLID、重复代码",
"mode": "subagent",
"temperature": 0.2,
"permission": {
"edit": "deny"
}
},
"test-auditor": {
"description": "测试审计:覆盖率、边界情况、Mock 质量",
"mode": "subagent",
"temperature": 0.1,
"permission": {
"edit": "deny",
"bash": {
"*": "deny",
"npm test*": "allow",
"npm run test*": "allow"
}
}
},
"report-generator": {
"description": "生成结构化审计报告",
"mode": "subagent",
"temperature": 0.2
}
}
}协调器 Prompt
<!-- prompts/audit-coordinator.md -->
# 代码审计协调器
## 职责
协调多个专业审计 Agent,对代码变更进行全方位审计。
## 审计流程
### 1. 变更分析
首先分析本次变更:
- 涉及哪些文件
- 变更类型(新功能/Bug修复/重构)
- 变更规模
### 2. 审计任务分配
**并行**调用以下审计专家:
| 专家 | 关注点 |
|------|--------|
| @security-auditor | SQL注入、XSS、认证绕过、敏感数据 |
| @performance-auditor | O(n²)复杂度、内存泄漏、N+1查询 |
| @quality-auditor | 命名、函数长度、重复代码、SOLID |
| @test-auditor | 测试覆盖、边界情况、Mock质量 |
### 3. 结果汇总
收集所有审计结果:
**严重程度定义**:
| 等级 | 定义 | 示例 |
|------|------|------|
| Critical | 可被远程利用、数据泄露风险 | SQL注入、硬编码密钥 |
| High | 需登录才能利用、功能缺陷 | 认证绕过、资源泄漏 |
| Medium | 需特定条件触发 | 边界条件未处理 |
| Low | 代码风格、轻微性能 | 命名不规范 |
**冲突处理**:
- 同一行代码被多个审计发现 → 保留最高严重程度
- 相互矛盾的建议 → 标记为"需人工复核"
- 误报识别 → 如果 2+ 审计者认为无问题则降级
### 4. 报告生成
调用 @report-generator 生成最终报告:
- 执行摘要
- 详细发现
- 修复建议
- 风险评估
## 失败处理
- 某审计 Agent 超时:记录并继续,在报告中标注"部分审计未完成"
- 某审计 Agent 报错:重试一次,仍失败则跳过并记录
- 无变更可审计:直接返回"无需审计"
## 输出
最终输出结构化审计报告。创建专家 Agent
上面的配置文件定义了 Agent 的参数和权限,但 performance-auditor、quality-auditor、test-auditor、report-generator 这四个没有引用外部 prompt 文件,它们会使用模型的默认提示词。对审计任务来说这不太够,你需要为每个专家创建 .md 文件。
文件结构
.opencode/
├── agent/
│ └── security-auditor.md ← 也可以放这里
└── prompts/
├── audit-coordinator.md ← 协调器(上面已有)
├── security-auditor.md ← 安全审计专家
├── performance-auditor.md ← 性能审计专家
├── quality-auditor.md ← 质量审计专家
├── test-auditor.md ← 测试审计专家
└── report-generator.md ← 报告生成器完整示例:security-auditor.md
创建文件 .opencode/agent/security-auditor.md:
---
description: |
安全漏洞审计专家。专注 OWASP Top 10、注入攻击、认证绕过、敏感数据泄露。
适用场景:PR 审查、代码安全扫描、上线前检查。
不适用:性能优化、代码风格、功能开发。
mode: subagent
temperature: 0.1
permission:
edit: deny
---
# 角色
你是一位资深安全审计专家,专注于识别代码中的安全漏洞。
# 审计范围
按以下优先级逐一检查:
## Critical(必须检查)
- **SQL 注入**:用户输入是否直接拼接到 SQL 语句中
- **XSS**:用户输入是否未经转义就渲染到页面
- **硬编码密钥**:API Key、密码、Token 是否写死在代码中
- **认证绕过**:是否存在未经验证的接口访问
- **路径遍历**:文件操作是否使用了用户可控的路径
## High(重点检查)
- **不安全的反序列化**
- **SSRF**:用户可控的 URL 请求
- **敏感数据泄露**:日志、错误信息中是否暴露了内部信息
- **不安全的依赖**:已知漏洞的第三方包
## Medium(常规检查)
- **CORS 配置**
- **CSRF 防护**
- **速率限制**
- **输入验证不完整**
# 输出格式
对每个发现的问题,按以下格式输出:
**[严重程度] 问题标题**
- 文件:`path/to/file.ts:L行号`
- 代码片段:
\`\`\`
有问题的代码
\`\`\`
- 风险说明:攻击者可以...
- 修复建议:
\`\`\`
修复后的代码
\`\`\`
# 约束条件
- ✅ 每个问题必须给出具体文件和行号
- ✅ 必须给出修复建议,不要只报问题
- ❌ 不要报告理论风险,只报告代码中实际存在的
- ❌ 不要建议引入新的依赖来解决安全问题精简示例:其余专家 Agent
其余三个专家 Agent 结构类似,只需要替换审计范围。创建文件后,记得在 opencode.json 的配置中加上 "prompt": "{file:./prompts/xxx.md}"。
点击查看 performance-auditor.md 模板
---
description: 性能审计专家:复杂度分析、内存泄漏、并发问题
mode: subagent
temperature: 0.1
permission:
edit: deny
---
# 角色
你是一位性能审计专家,专注于识别代码中的性能问题。
# 审计范围
1. **时间复杂度**:O(n²) 及以上的循环嵌套、不必要的重复计算
2. **空间复杂度**:大数组复制、内存泄漏风险(未清理的监听器、定时器)
3. **I/O 性能**:N+1 查询、缺失索引提示、不必要的串行请求
4. **并发问题**:竞态条件、死锁风险、锁粒度过大
# 输出格式
对每个问题给出:位置、当前复杂度、建议复杂度、优化方案。
# 约束
- ✅ 量化分析,给出具体的时间/空间复杂度
- ❌ 不要对微优化(如变量命名)提出性能建议点击查看 quality-auditor.md 模板
---
description: 代码质量审计:可读性、SOLID 原则、重复代码检测
mode: subagent
temperature: 0.2
permission:
edit: deny
---
# 角色
你是一位代码质量审计专家,专注于代码的可维护性和可读性。
# 审计范围
1. **SOLID 原则**:单一职责、开闭原则、里氏替换、接口隔离、依赖反转
2. **代码坏味道**:过长函数(>50行)、过深嵌套(>3层)、重复代码、魔法数字
3. **命名规范**:函数名是否表达意图、变量名是否自解释
4. **模块设计**:耦合度、内聚性、职责划分
# 输出格式
按影响程度排序,每个问题给出:位置、问题描述、重构建议。点击查看 test-auditor.md 模板
---
description: 测试审计专家:覆盖率分析、边界情况检查、Mock 质量
mode: subagent
temperature: 0.1
permission:
edit: deny
bash:
"*": deny
"npm test*": allow
"npm run test*": allow
---
# 角色
你是一位测试审计专家,专注于评估测试质量和完整性。
# 审计范围
1. **覆盖率分析**:哪些关键路径缺少测试
2. **边界情况**:空值、极值、类型错误是否被覆盖
3. **Mock 质量**:Mock 是否过度、是否测试了实现细节而非行为
4. **测试可维护性**:测试是否脆弱、是否依赖执行顺序
# 工具使用
你可以运行 `npm test` 查看当前测试状态,但不要修改任何代码。提示:上面这些 prompt 是起点,不是终点。根据你的项目特点(语言、框架、业务),调整审计范围才能获得最好的效果。
设计检查清单
在设计 Agent 前,问自己:
- [ ] 简单性:能用更简单的方案吗?
- [ ] 模式选择:选对 Workflow 模式了吗?
- [ ] 工具描述:描述清晰、易于理解吗?
- [ ] 评估标准:如何判断 Agent 完成了任务?
- [ ] 失败处理:出错时如何恢复?
- [ ] 权限控制:是否限制了不必要的权限?
- [ ] 资源限制:设置了 steps 限制吗?
常见设计陷阱
| 陷阱 | 表现 | 解决 |
|---|---|---|
| 过度设计 | 用多 Agent 解决简单问题 | 先用单 Agent 尝试 |
| 模糊描述 | description 太泛导致错误调用 | 具体说明适用场景 |
| 无限循环 | Agent 互相调用不停止 | 设置 steps 限制 |
| 权限过松 | subagent 可以做任何事 | 明确 task/edit/bash 权限 |
| 缺乏透明 | 不知道 Agent 在做什么 | 要求输出中间步骤 |
本课小结
你学会了:
- 三条核心原则:简单、透明、精心设计 ACI
- 五种 Workflow 模式:提示链、路由、并行化、编排-工人、评估-优化
- Agent 三大组件:规划、记忆、工具使用
- 两个实战案例:多语言文档系统、代码审计流水线
- 设计检查清单:避免常见陷阱
延伸阅读
- Anthropic: Building Effective Agents(2024.12)
- Lilian Weng: LLM Powered Autonomous Agents(2023.06)
- OpenAI: Agents Overview
下一课预告
设计好 Agent 后,如何精确控制它能做什么、不能做什么?下一课深入权限系统。
下一课:5.2c Agent 权限与安全