5.3b Skill 进阶
本课深入 Skill 的高级用法:渐进式披露的三层结构、可执行脚本、5 步创建流程、测试验证和真实案例。
📝 课程笔记
本课核心知识点整理:
学完你能做什么
- 设计三层渐进式披露结构
- 在 Skill 中集成可执行脚本
- 按 5 步流程创建高质量 Skill
- 系统化测试和验证 Skill
- 借鉴真实案例优化自己的 Skill
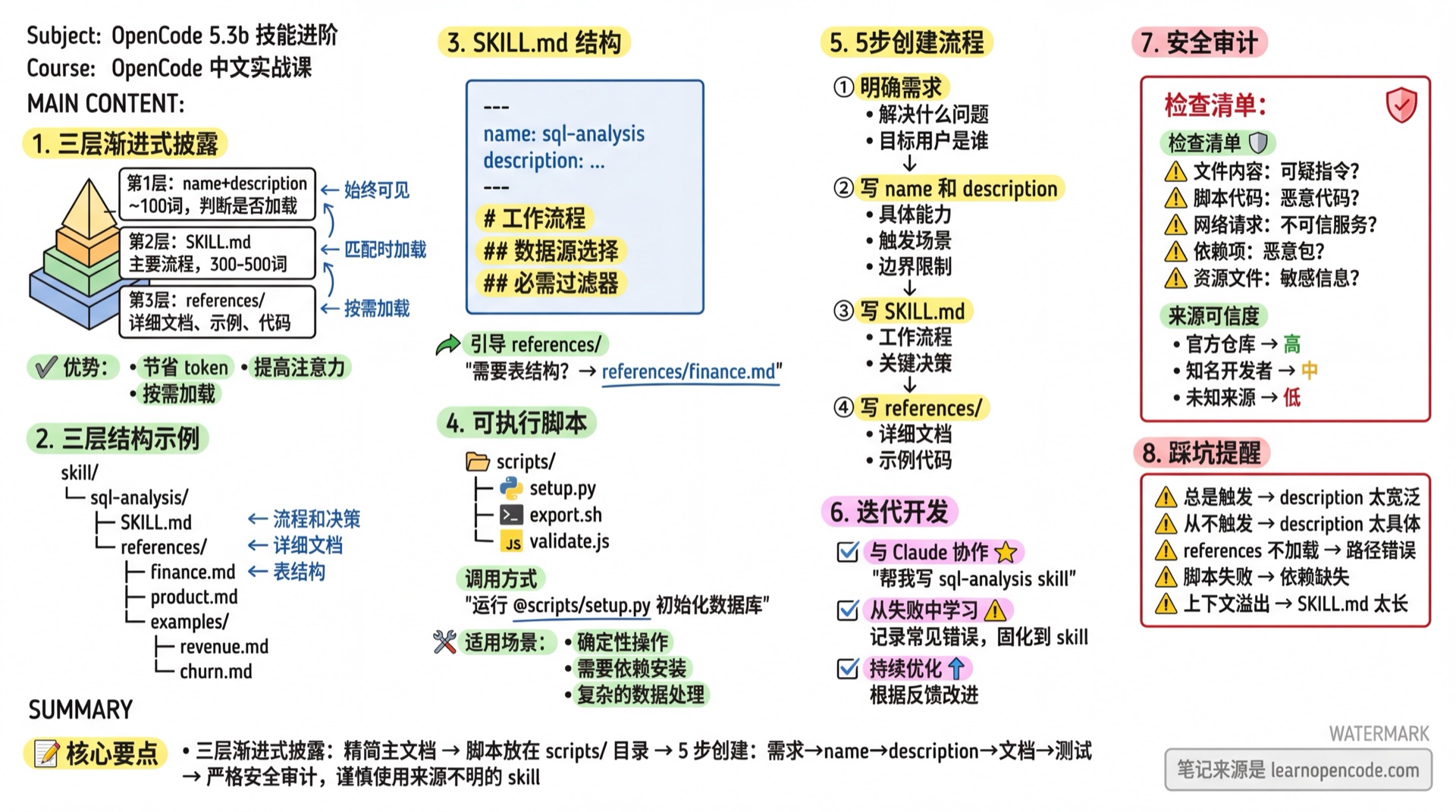
渐进式披露的三层结构
为什么需要分层
想象你的 Skill 包含:
- 10 个表的详细结构
- 50 个常用查询示例
- 各种边缘情况处理
如果把这些全部塞进 SKILL.md,会导致:
- 上下文窗口快速耗尽
- 模型注意力被无关内容分散
- Token 费用飙升
解决方案:像组织一本手册那样组织 Skill:
目录(始终可见) → 章节(按需阅读) → 速查手册(需要时查阅)三层结构详解
skill/
└── sql-analysis/
├── SKILL.md # 第二层:主要工作流程
└── references/ # 第三层:详细文档
├── finance.md # 财务表结构
├── product.md # 产品表结构
├── sales.md # 销售表结构
└── examples/
├── revenue-queries.md # 收入查询示例
└── churn-queries.md # 流失分析示例第一层:name + description(~100 词)
- 始终加载到
<available_skills>中 - 用于判断是否需要加载此 Skill
第二层:SKILL.md 正文
- 任务匹配时加载
- 包含工作流程、关键逻辑、决策树
- 保持精简(建议 300-2000+ 词)
第三层:references/ 目录
- 仅在需要具体细节时加载
- Claude 通过读取文件按需获取
- 可以包含大量详细信息
实现示例
SKILL.md(第二层):
---
name: sql-analysis
description: 用于分析业务数据:收入、ARR、客户分群、产品使用。
---
# SQL 分析技能
## 工作流程
1. 明确分析需求
2. 选择正确的数据源
3. 应用标准过滤器
4. 验证结果
## 数据源选择
| 分析类型 | 推荐表 | 详细文档 |
|---------|-------|---------|
| 收入分析 | monthly_revenue | `references/finance.md` |
| 产品使用 | daily_usage | `references/product.md` |
| 销售管道 | pipeline_snapshot | `references/sales.md` |
## 必需过滤器
所有查询必须:
- 排除测试账户:`account != 'Test'`
- 只用完整周期
需要具体表结构或查询示例时,读取 references/ 中的对应文件。references/finance.md(第三层):
# 财务表详细结构
## monthly_revenue 表
| 字段 | 类型 | 说明 |
|-----|------|------|
| account_id | STRING | 账户 ID |
| month | DATE | 月份(每月第一天) |
| mrr | FLOAT | 月度经常性收入 |
| arr | FLOAT | 年度经常性收入 |
| segment | STRING | 客户分群 |
## 常用查询
### 按分群统计月收入
```sql
SELECT
segment,
DATE_TRUNC(month, MONTH) as period,
SUM(mrr) as total_mrr
FROM monthly_revenue
WHERE account_id != 'Test'
GROUP BY 1, 2
ORDER BY 2 DESC, 3 DESC计算环比增长
...(更多查询示例)
**关键原则**:信息只放在 SKILL.md 或 references/ 其中之一,不要重复。
---
## 可执行脚本支持
### 为什么需要脚本
某些操作用代码执行比用 Token 生成更高效、更可靠:
| 任务 | Token 生成 | 代码执行 |
|------|-----------|---------|
| 排序 1000 个数字 | 大量 Token、可能出错 | 毫秒级、100% 准确 |
| 解析 PDF 表单字段 | 需要把 PDF 加载到上下文 | 直接处理文件 |
| 格式转换 | 容易格式错乱 | 确定性输出 |
### 脚本目录结构
skill/ └── pdf-skill/ ├── SKILL.md ├── references/ │ └── forms.md └── scripts/ ├── extract_form_fields.py ├── merge_pdfs.py └── convert_to_images.py
### SKILL.md 中引用脚本
```markdown
---
name: pdf
description: PDF 处理工具包:提取文本和表格、创建新 PDF、合并拆分文档、处理表单。
---
# PDF 处理技能
## 提取表单字段
无需将 PDF 加载到上下文,直接运行脚本:
```bash
python scripts/extract_form_fields.py input.pdf输出示例:
{
"fields": [
{"name": "full_name", "type": "text", "value": ""},
{"name": "date", "type": "date", "value": ""}
]
}合并多个 PDF
python scripts/merge_pdfs.py file1.pdf file2.pdf -o output.pdf转换为图片
python scripts/convert_to_images.py document.pdf --output-dir ./images详细参数说明见 references/scripts-guide.md。
### 脚本编写原则
1. **独立可运行**:脚本应该能独立执行,不依赖复杂环境
2. **清晰的输入输出**:明确的参数和返回格式
3. **错误处理**:优雅处理异常情况
4. **最小依赖**:只使用必要的库
**示例脚本**(`scripts/extract_form_fields.py`):
```python
#!/usr/bin/env python3
"""提取 PDF 表单字段信息"""
import sys
import json
def extract_fields(pdf_path: str) -> dict:
"""提取 PDF 中的表单字段"""
try:
# 使用 PyPDF2 或其他库
from pypdf import PdfReader
reader = PdfReader(pdf_path)
fields = reader.get_fields() or {}
result = []
for name, field in fields.items():
result.append({
"name": name,
"type": str(field.get("/FT", "unknown")),
"value": str(field.get("/V", ""))
})
return {"fields": result, "count": len(result)}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
if len(sys.argv) < 2:
print(json.dumps({"error": "Usage: extract_form_fields.py <pdf_path>"}))
sys.exit(1)
result = extract_fields(sys.argv[1])
print(json.dumps(result, indent=2, ensure_ascii=False))5 步创建流程
步骤 1:明确需求
在写任何内容之前,回答这些问题:
| 问题 | 目的 |
|---|---|
| 这个 Skill 解决什么具体问题? | 明确价值 |
| 什么情况下应该触发? | 设计 description |
| 成功的输出是什么样? | 定义验收标准 |
| 有哪些边缘情况? | 避免遗漏 |
好的候选场景:
- 跨项目复用的知识
- 多人都需要的流程
- 不常变化的稳定模式
不适合做 Skill 的:
- 只用一次的任务
- 频繁变化的内容
- 项目特定的规范(用 CLAUDE.md)
步骤 2:写 name
name: sql-analysis命名原则:
- 简短清晰
- 小写字母和数字
- 用单个连字符分隔
- 反映核心功能
步骤 3:写 description(最重要)
description 决定触发,是最关键的部分。
差的 description:
description: 帮助处理数据问题:太模糊,什么算"处理数据"?
好的 description:
description: 从 PDF 中提取表格并转换为 CSV 格式,用于数据分析工作流。当需要填写 PDF 表单或批量处理 PDF 文档时使用。不用于简单 PDF 查看或基本格式转换。description 要素清单:
| 要素 | 示例 |
|---|---|
| 具体能力 | "提取表格并转换为 CSV" |
| 触发场景 | "当需要填写 PDF 表单时" |
| 使用对象 | "用于数据分析工作流" |
| 边界限制 | "不用于简单 PDF 查看" |
步骤 4:写主要指令
结构化、可扫描、可操作:
# SQL 分析技能
## 工作流程
1. **明确需求**
- 时间范围?(默认当年)
- 客户分群?
- 用于什么决策?
2. **选择数据源**
- 优先汇总表
- 确认必需字段存在
3. **执行查询**
- 应用标准过滤器
- 验证结果合理性
## 标准过滤器
所有查询必须包含:
- `WHERE account_id != 'Test'`
- `WHERE month <= DATE_TRUNC(CURRENT_DATE(), MONTH)`
## 详细文档
- 表结构 → `references/tables.md`
- 查询示例 → `references/examples.md`写作原则:
| 原则 | 说明 |
|---|---|
| 用 Markdown 结构 | 标题、列表、表格增加可读性 |
| 提供具体示例 | 代码块展示正确用法 |
| 说明不能做什么 | 避免误用 |
| 引用详细文档 | 保持主文件精简 |
步骤 5:测试验证
系统化测试 Skill,确保它在各种场景下都能正常工作。
测试矩阵
| 测试类型 | 测试内容 | 预期结果 | 优先级 |
|---|---|---|---|
| 触发测试 | "帮我查询上季度收入" | Skill 激活 | P0 |
| 边界测试 | "查询收入"(无时间范围) | 询问后执行 | P1 |
| 负向测试 | "帮我写一封邮件" | 不激活 | P0 |
| 输出测试 | 验证输出格式是否符合规范 | 格式正确 | P1 |
| 错误测试 | 故意输入错误参数 | 优雅报错 | P2 |
触发测试
# ✅ 应该激活的请求
"使用 sql-analysis 技能分析数据" → 显式请求,必须激活
"帮我看看上季度的 ARR 变化" → 自然请求,语义匹配激活
"收入趋势分析" → 关键词匹配,应该激活
# ❌ 不应该激活的请求
"帮我写 SQL 教程" → 是教学,不是分析
"数据库性能调优" → 超出边界(description 已说明不适用)
"创建新表" → DDL 操作,不适用功能测试
| 检查项 | 测试方法 | 通过标准 |
|---|---|---|
| 输出一致性 | 相同输入运行 3 次 | 核心内容一致 |
| 新手可用性 | 让不熟悉领域的人尝试 | 能成功完成任务 |
| 文档准确性 | 按示例操作 | 结果与示例一致 |
| 引用完整性 | 检查 references/ 路径 | 所有引用都存在 |
测试脚本(可选)
创建 .opencode/skill/<name>/test.sh:
#!/bin/bash
# Skill 自动测试脚本
echo "=== 触发测试 ==="
# 测试 1: 正常触发
opencode --prompt "帮我查询上季度收入" --check-skill "sql-analysis"
# 测试 2: 负向测试
opencode --prompt "帮我写邮件" --expect-no-skill "sql-analysis"
echo "=== 功能测试 ==="
# 测试输出格式
opencode --prompt "分析 ARR" | grep -q "## ARR 计算" && echo "✅ 输出格式正确"测试清单
完成以下检查后,Skill 可以投入使用:
- [ ] 触发测试:3 个正向用例都能激活
- [ ] 负向测试:3 个边界用例都不激活
- [ ] 输出测试:输出格式符合预期
- [ ] 新手测试:非专业人员能成功使用
- [ ] 引用测试:所有 references/ 文件都存在
- [ ] 错误测试:输入错误时有明确提示
迭代开发方法
与 Claude 协作创建 Skill
不要从零开始写,让 Claude 帮你提取知识:
用户:帮我创建一个数据仓库技能。我会描述我们的表和业务逻辑,你帮我结构化。
Claude:好的,请告诉我:
1. 你们主要的数据表有哪些?
2. 有哪些常用的业务术语需要定义?
3. 查询时必须遵守的规则是什么?
[对话继续,Claude 提问并整理信息]
Claude:根据我们的讨论,这是 SKILL.md 的结构:
...从失败中学习
当 Skill 执行出错时:
用户:这个查询结果不对,它没有排除测试账户
Claude:让我反思一下问题:
1. 标准过滤器没有被应用
2. 可能是因为指令不够明确
建议更新 SKILL.md:
- 在"必需过滤器"部分加粗强调
- 添加"绝对不能遗漏"的警告把这些反思固化到 Skill 中。
持续优化
1. 在工作中使用 Skill
2. 记录成功的模式和失败的情况
3. 定期回顾并更新 Skill
4. 分享给团队成员真实案例
案例 1:DOCX 创建技能
---
name: docx
description: "文档创建、编辑和分析,支持修订、批注、格式保留和文本提取。当 Claude 需要处理 .docx 文件时使用:(1) 创建新文档 (2) 修改内容 (3) 处理修订 (4) 添加批注"
license: Proprietary. LICENSE.txt has complete terms
---
# DOCX 创建、编辑和分析
## 概述
用户可能要求创建、编辑或分析 .docx 文件。.docx 本质上是包含 XML 文件的 ZIP 压缩包。
## 工作流程决策树
### 读取/分析内容
使用下面的"文本提取"或"原始 XML 访问"部分
### 创建新文档
使用"创建新 Word 文档"工作流程
### 编辑现有文档
- **你自己的文档 + 简单修改**:使用"基础 OOXML 编辑"
- **别人的文档**:使用**修订工作流程**(推荐默认)
- **法律、学术、商业、政府文档**:**必须**使用修订工作流程
## 文本提取
使用 pandoc 转换为 markdown:
```bash
pandoc --track-changes=all path-to-file.docx -o output.md创建新 Word 文档
使用 docx-js,必须先读取 docx-js.md 完整文件。
详细文档
- OOXML 编辑 →
ooxml.md - docx-js 语法 →
docx-js.md
**这个 Skill 的亮点**:
- 清晰的决策树帮助选择正确工作流程
- 区分不同场景的处理方式
- 引用详细文档而不是全部内联
### 案例 2:前端设计技能
来源:[Anthropic Engineering Blog](https://claude.com/blog/improving-frontend-design-through-skills)
```markdown
---
name: frontend-design
description: 创建独特的、生产级的前端界面。用于构建 Web 组件、页面或应用。生成有创意、精致的代码,避免通用的 AI 美学。
license: Complete terms in LICENSE.txt
---
# 前端设计技能
## 设计思考
编码前,理解上下文并确定**大胆的美学方向**:
- **目的**:这个界面解决什么问题?谁在使用?
- **风格**:选择一个极端:极简主义、极繁主义、复古未来、自然有机、奢华精致、俏皮玩具风、编辑杂志风...
- **差异化**:什么让这个设计令人难忘?
## 前端美学指南
### 排版
选择独特的字体。避免 Arial、Inter 等通用字体。
推荐:JetBrains Mono、Playfair Display、IBM Plex、Bricolage Grotesque
### 配色
承诺一个统一的美学。使用 CSS 变量保持一致性。
主色配锐利的强调色,优于均匀分布的温和色板。
### 动效
使用动画增加效果和微交互。
一个精心编排的页面加载(错开显示)比分散的微交互更令人愉悦。
### 背景
创造氛围和深度,而不是默认纯色。
渐变网格、噪点纹理、几何图案、分层透明度。
## 绝对避免
- Inter、Roboto、Arial、系统字体
- 白底紫色渐变(AI 典型美学)
- 可预测的布局和组件模式
- 缺乏上下文特色的模板设计这个 Skill 的亮点:
- 明确问题(AI 生成的通用美学)
- 提供具体的替代方案
- 有"绝对避免"清单
案例 3:品牌指南技能
---
name: brand-guidelines
description: 应用公司官方品牌色和排版。用于创建需要公司视觉风格的任何内容:文档、演示、界面。
---
# 品牌规范
## 颜色
**主色**:
- 深色:`#141413`
- 浅色:`#faf9f5`
- 中灰:`#b0aea5`
**强调色**:
- 橙色:`#d97757`
- 蓝色:`#6a9bcc`
- 绿色:`#788c5d`
## 字体
- **标题**:Poppins(24pt 及以上)
- **正文**:Lora
- **备选**:Arial / Georgia
## 应用规则
- 标题用 Poppins,正文用 Lora
- 根据背景智能选择文字颜色
- 非文字形状使用强调色循环这个 Skill 的亮点:
- 精确的数值(十六进制色值、字号)
- Claude 本身不知道的信息
- 简洁直接
安全审计
为什么需要审计
Skill 可以:
- 给 Claude 提供指令
- 包含可执行代码
- 引导 Claude 访问网络资源
恶意 Skill 可能导致数据泄露或系统损坏。
安全审计清单
| 检查项 | 检查内容 | 风险 |
|---|---|---|
| 文件内容 | 阅读所有 .md 文件 | 是否有可疑指令 |
| 脚本代码 | 审查 .py/.js 等文件 | 是否有恶意代码 |
| 网络请求 | 检查 URL 和 API 调用 | 是否连接不可信服务 |
| 依赖项 | 查看 import/require | 是否引入恶意包 |
| 资源文件 | 检查图片、数据文件 | 是否包含敏感信息 |
来源可信度
| 来源 | 可信度 | 建议 |
|---|---|---|
| 官方仓库 | 高 | 可直接使用 |
| 知名开发者 | 中 | 快速审查后使用 |
| 未知来源 | 低 | 完整审计后使用 |
| 网络下载 | 未知 | 谨慎使用 |
审计示例
# 1. 查看所有文件
find my-skill/ -type f -name "*.md" -o -name "*.py" -o -name "*.js"
# 2. 检查是否有网络请求
grep -r "http" my-skill/
grep -r "fetch\|requests\|urllib" my-skill/
# 3. 检查是否有文件系统操作
grep -r "open\|write\|delete\|remove" my-skill/
# 4. 检查依赖
cat my-skill/requirements.txt
cat my-skill/package.json踩坑提醒
| 现象 | 原因 | 解决 |
|---|---|---|
| Skill 总是触发 | description 太宽泛 | 添加边界限制:"不用于 X" |
| Skill 从不触发 | description 太具体 | 增加更多触发场景 |
| 多个 Skill 冲突 | description 重叠 | 明确区分各自职责 |
| references 不加载 | 路径写错 | 使用相对路径如 references/xxx.md |
| 脚本执行失败 | 依赖缺失 | 确保环境有必要的包 |
| 输出不一致 | 指令模糊 | 添加具体示例和验证步骤 |
| 上下文溢出 | SKILL.md 太长 | 拆分到 references/ |
本课小结
你学会了:
三层渐进式披露
- 第一层:name + description(始终可见)
- 第二层:SKILL.md 正文(任务匹配时加载)
- 第三层:references/(按需加载)
可执行脚本
- 适合确定性操作
- 放在
scripts/目录 - 在 SKILL.md 中说明如何调用
5 步创建流程
- 明确需求 → 写 name → 写 description → 写指令 → 测试验证
迭代开发
- 与 Claude 协作提取知识
- 从失败中学习并固化到 Skill
安全审计
- 检查文件、脚本、网络、依赖
- 优先使用可信来源
延伸阅读
下一课预告
下一课我们将学习 Skill 高级模式。
你会学到:
- Skill 与 MCP 协作模式(厨房 vs 菜谱)
- 五种工作流模式:顺序编排、多 MCP 协调、迭代优化等
- 分发共享策略(GitHub、API)
- 企业级 Skill 设计最佳实践